Heute hatte ich eine interessante Wissensmanagement-Übung (unser neuer Übungsleiter hat Informatik und Philosophie studiert - wenn das nicht verspricht, interessant zu werden, weiß ich auch nicht ;) )...
Und er nannte del.icio.us und flickr als Beispiele für die Externalisierung von Wissen (sprich, seine Gedanken zu Papier bringen) und das "tagging", also das freie Vergeben von Kategorienamen für jeden Eintrag, als Möglichkeit, implizites Wissen im Computer explizit zu speichern.
Diesen Hinweis fand ich interessant und habe mir mal ein paar Gedanken gemacht, wieso Tagging für diese Zwecke so gut geeignet ist.
Wie ich finde, wurde mit den "Tags" ein bestechend einfaches Konzept verwirklicht, auf das lange Zeit erstaunlicherweise niemand gekommen ist:
<!--more-->
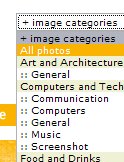 Früher dachte man, es wäre erforderlich, dass die Admins/Anbieter alle denkbaren Kategorienamen im Voraus zu erahnen und in eine Baumstruktur zu quetschen (Beispiel rechts: Stock Exchange). Die Folge war, dass die Benutzer aus verschiedenen Gründen dieses System nicht effektiv verwendeten oder es umgingen: Zum einen gab es schlicht Bildmotive, Bookmarks, oder welches Datum auch immer, die von keiner Kategorie genau getroffen wurden. Mag sein, dass die Phantasie des Admins zu gering war (oder er die Kategoriestruktur klein halten wollte), mag sein, dass die Assoziationen des Benutzers anders waren, er es also in einen anderen Kontext bringen wollte. In jedem Fall sortierte der Benutzer seinen neuen Eintrag in eine Kategorie, die möglicherweise nicht mal annähernd den Sinn traf - im einen Fall, weil ein Bild eines Pärchens vor dem Eifelturm eben gerade nicht in der Kategorie "Bauwerke" landen sollte, sondern der Benutzer "Paris" und "Liebe" damit verband und es aus Mangel an Kategorien in "Reisen, allgemein" einsortieren musste.
Im anderen Fall, weil die vier Kategorien "Menschen", "Objekte", "Bewegung", "Fotomontagen" allenfalls annähernd umreißen, welche Motive zu finden sein werden. Der Informationsgehalt dieser "Spareinteilung" tendiert gegen Null; man hätte die Bilder auch alle in einen Topf werfen können.
Zudem ist die unendliche Faulheit des Benutzers niemals zu unterschätzen: Die Kategorisierung von Inhalt dient dem Benutzer nicht gegenwärtig (nämlich erst später, wenn er wieder danach sucht). Er ist auch nicht derart sozial eingestellt, dass er die Kategorisierung zum Wohle der Allgemeinheit auf sich nimmt. Nein: Er möchte einfach nur ein Bild hochladen oder eine Internetadresse bookmarken. Nicht mehr, nicht weniger, und alles am besten gestern. Da klickt sich keiner durch einen riesigen Kategoriebaum und sucht die am besten passenden Einträge heraus. Das dauert zu lange, und der Sinn wird - jedenfalls gegenwärtig - nicht erkennbar.
Früher dachte man, es wäre erforderlich, dass die Admins/Anbieter alle denkbaren Kategorienamen im Voraus zu erahnen und in eine Baumstruktur zu quetschen (Beispiel rechts: Stock Exchange). Die Folge war, dass die Benutzer aus verschiedenen Gründen dieses System nicht effektiv verwendeten oder es umgingen: Zum einen gab es schlicht Bildmotive, Bookmarks, oder welches Datum auch immer, die von keiner Kategorie genau getroffen wurden. Mag sein, dass die Phantasie des Admins zu gering war (oder er die Kategoriestruktur klein halten wollte), mag sein, dass die Assoziationen des Benutzers anders waren, er es also in einen anderen Kontext bringen wollte. In jedem Fall sortierte der Benutzer seinen neuen Eintrag in eine Kategorie, die möglicherweise nicht mal annähernd den Sinn traf - im einen Fall, weil ein Bild eines Pärchens vor dem Eifelturm eben gerade nicht in der Kategorie "Bauwerke" landen sollte, sondern der Benutzer "Paris" und "Liebe" damit verband und es aus Mangel an Kategorien in "Reisen, allgemein" einsortieren musste.
Im anderen Fall, weil die vier Kategorien "Menschen", "Objekte", "Bewegung", "Fotomontagen" allenfalls annähernd umreißen, welche Motive zu finden sein werden. Der Informationsgehalt dieser "Spareinteilung" tendiert gegen Null; man hätte die Bilder auch alle in einen Topf werfen können.
Zudem ist die unendliche Faulheit des Benutzers niemals zu unterschätzen: Die Kategorisierung von Inhalt dient dem Benutzer nicht gegenwärtig (nämlich erst später, wenn er wieder danach sucht). Er ist auch nicht derart sozial eingestellt, dass er die Kategorisierung zum Wohle der Allgemeinheit auf sich nimmt. Nein: Er möchte einfach nur ein Bild hochladen oder eine Internetadresse bookmarken. Nicht mehr, nicht weniger, und alles am besten gestern. Da klickt sich keiner durch einen riesigen Kategoriebaum und sucht die am besten passenden Einträge heraus. Das dauert zu lange, und der Sinn wird - jedenfalls gegenwärtig - nicht erkennbar.
 Von diesen starren Strukturen hat man sich mit dem Tagging gelöst: Zu jedem Bild oder Bookmark kann man nun "frei assoziieren". Man wählt beliebige Schlagworte, die automatisch zu einer Kategorie werden. In der logischen Folge hat also jeder Benutzer seinen eigenen "Kategoriehaufen": Er kann ihn nach Belieben anlegen, verändern, oder auch alle Einträge gleich taggen. Das führt dazu, dass man durch eine Suche nach dem Tag "Paris" über alle Benutzer all jene Einträge finden wird, mit denen der jeweilige Benutzer eben "Paris" assoziiert hat. Einziger Wermutstropfen: Durch die freie Assoziation kommt es dazu, dass verschiede Benutzer denselben Sachverhalt unterschiedlich, möglicherweise synonym, benennen (siehe etwa das Beispiel von Slashdot, das oft in "News", "Tech-News" oder auch "Technology" einsortiert wird).
Das Problem kann man aber durch eine Volltextsuche über andere Metadaten einschränken. Oder man nutzt es geschickt für sich, indem man den Benutzern durch die fremden Assoziationen möglicherweise Inspiration verschafft: Obiges Slashdot-Beispiel zeigt uns die Assoziationen anderer Benutzer mit diesem Link, und wir können durch Klick auf deren Tags auf neue Gedanken und weitere Links kommen. Social Mindmapping, sozusagen.
Von diesen starren Strukturen hat man sich mit dem Tagging gelöst: Zu jedem Bild oder Bookmark kann man nun "frei assoziieren". Man wählt beliebige Schlagworte, die automatisch zu einer Kategorie werden. In der logischen Folge hat also jeder Benutzer seinen eigenen "Kategoriehaufen": Er kann ihn nach Belieben anlegen, verändern, oder auch alle Einträge gleich taggen. Das führt dazu, dass man durch eine Suche nach dem Tag "Paris" über alle Benutzer all jene Einträge finden wird, mit denen der jeweilige Benutzer eben "Paris" assoziiert hat. Einziger Wermutstropfen: Durch die freie Assoziation kommt es dazu, dass verschiede Benutzer denselben Sachverhalt unterschiedlich, möglicherweise synonym, benennen (siehe etwa das Beispiel von Slashdot, das oft in "News", "Tech-News" oder auch "Technology" einsortiert wird).
Das Problem kann man aber durch eine Volltextsuche über andere Metadaten einschränken. Oder man nutzt es geschickt für sich, indem man den Benutzern durch die fremden Assoziationen möglicherweise Inspiration verschafft: Obiges Slashdot-Beispiel zeigt uns die Assoziationen anderer Benutzer mit diesem Link, und wir können durch Klick auf deren Tags auf neue Gedanken und weitere Links kommen. Social Mindmapping, sozusagen.
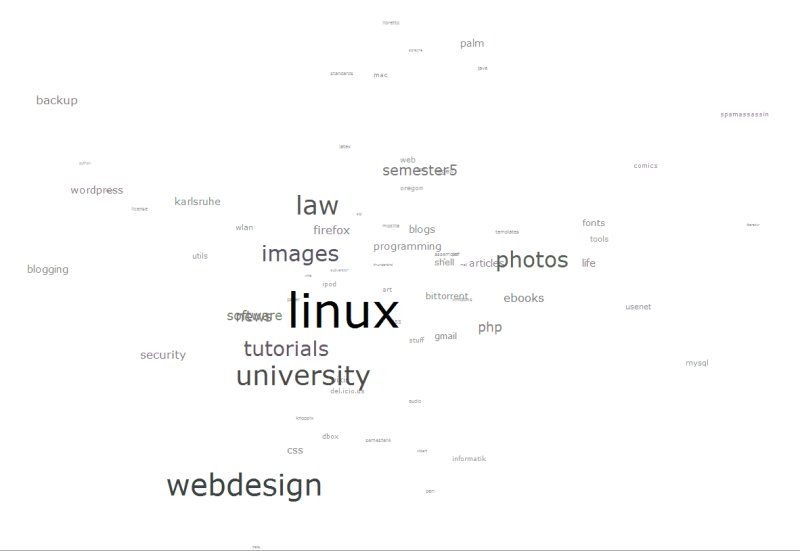 Mit der Wichtigkeit von Tags kann man dann nette Visualisierungen machen, etwa diese "Tag-Wolke" rechts, hier am Beispiel meines del.icio.us-Accounts. Auch bei flickr werden die "popular tags" unterschiedlich groß angezeigt, sodass man direkt erkennen kann, wie wichtig den anderen Benutzern der jeweilige Begriff war. Durch das Lösen von einer hierarchischen (Baum-)Struktur fällt es uns erheblich leichter, solche Sachverhalte intuitiv zu visualisieren (also nicht durch eine absolute Zahl oder einen Prozentwert hinter dem Namen), denn es gibt keine Reihenfolge mehr, die wir einhalten müssten.
Mit der Wichtigkeit von Tags kann man dann nette Visualisierungen machen, etwa diese "Tag-Wolke" rechts, hier am Beispiel meines del.icio.us-Accounts. Auch bei flickr werden die "popular tags" unterschiedlich groß angezeigt, sodass man direkt erkennen kann, wie wichtig den anderen Benutzern der jeweilige Begriff war. Durch das Lösen von einer hierarchischen (Baum-)Struktur fällt es uns erheblich leichter, solche Sachverhalte intuitiv zu visualisieren (also nicht durch eine absolute Zahl oder einen Prozentwert hinter dem Namen), denn es gibt keine Reihenfolge mehr, die wir einhalten müssten.
Dieselbe Organisationsidee mit Tags ist übrigens auch auf Weblogs anwendbar: Denn auch solche Einträge entstehen mehr spontan, sodass man vorher nie wissen kann, ob man seine Kategorien richtig gewählt hat. So gibt es zum Beispiel ein Freetag-Plugin für Serendipity, das Artikel "taggbar" macht. Und auch im Mailbereich ist das möglich: Ordnerstrukturen haftet dasselbe Problem an wie starren Kategorien. Google hat das in seinem GMail-System erkannt und nennt seine Mail-Tags "Labels" (GMail-Login nötig). (Dass GMail einen IMAP-Dienst mit virtuellen "Ordnern" anhand der Tags anbieten sollte, wäre die logische Konsequenz, die leider bis heute noch auf sich warten lässt...).
Fazit: Wenn wir unsere Gedanken schon in Worte fassen müssen, um sie in einen Computer zu speichern (und das wird noch länger so bleiben), dann müssen wir das über Strukturen tun, bei denen sich der Computer den Gedanken anpasst, nicht umgekehrt. Denn das menschliche Denken ist netz-, nicht baumförmig. Und schon gar nicht linear. Spontanität statt Planung, Assoziation statt Suche. Wann immer es um Sozialisierung von Wissen geht (das heißt: von Mensch zu Mensch) können wir alltägliche Nutzbarkeit, Einfachheit und damit letztlich Spaß an der Benutzung durch Systeme wie das "Tagging" erreichen.
Update: Wer noch ein paar Links mehr zum Thema "social software" sucht, wird vielleicht beim Social Software Seminar an der FH Aachen fündig. (Dort ist dieser Artikel hier z.B. auch verlinkt).